과적합과 일반화
- 데이터 학습량에 따른 과적합과 일반화 간단 분류
- Underfitting < Generalization < Overfitting
- 단순한 모델
Generalization (일반화)
- 모델이 새로운 데이터셋(Test data )에 대하여 정확히 예측하면 이것을 일반화 되었다고 말한다.
- 모델이 훈련 데이터로 평가한 결과와 테스트 데이터로 평가한 결과의 차이가 거의 없고 좋은 평가지표를 보여준다.
Overfitting (과대적합)
개념
- 학습할 때는 예측 성능이 너무 좋지만 일반성이 떨어져 새로운 데이터(Test data)에 대해선 성능이 좋지 않는 것
- Train 데이터를 너무 잘 맞추려고 해서 이상치까지 고려를 해버리게 된다.
- 쓸데 없는 것(이상치)까지 학습해서 헷깔리는 현상
원인
- 학습 데이터 양에 비해 모델이 너무 복잡한 경우 발생.
- 복잡한 모델이 만들어진다.
- Train Set 성능 ↑ but Validation Set 성능 ↓↓
- Train Set에서는 성능이 좋지만 Validation Set에서는 Train Set에 비해 너무 성능이 안좋다.
Underfitting (과소적합)
개념
- 모델이 훈련 데이터과 테스트 데이터셋 모두에서 성능이 안좋은 것을 말한다.
- Train 데이터를 사용을 덜 해서 분류해야 하는 것도 하질 못했다.
- 학습이 아직 덜 된 것
원인
- 데이터 양에 비해서 모델이 너무 단순한 경우 발생
- 단순한 모델이 만들어진다.
- Train Set 성능 ↓, Validation Set 성능 ↓
- Train Set에도 Validation Set에도 성능이 안좋은 모델
규제 하이퍼파라미터
- 주로 정수 값
- 모델의 복잡도를 규제하는 hyper parameter
- Hyper Parameter
- 모델의 성능에 영향을 끼치는 파라미터 값으로 모델 생성시 사람이 직접 지정해 주는 값
- Hyper Parameter Tunning
- 모델의 성능을 가장 높일 수 있는 하이퍼파라미터를 찾는 작업
- Parameter
- 머신러닝에서 파라미터는 모델이 데이터 학습을 통해 직접 찾아야 하는 값을 말한다.
- Hyper Parameter
graphviz 를 이용해서 트리 구조 시각화 하기
Graphviz 란
- 다이어그램을 그리는 툴
설치 방법
- 설치: https://graphviz.org/
- download
- 다음
- 동의함
- install option에서 환경변수를 잡아주기 위해 마지막 버튼인 Add Graphviz to the system PATH for current user를 선택한다
- 설치후 (컴파일 과정을 거친다)
- 명령프롬프트 관리자 권한 실행
dot -c를 입력한다- 완료
- graphviz 설치
conda activate를 통해 가상환경에 접속한다pip install graphviz를 입력한다- jupyter notebook 을 실행시키면 적용
- 순서도
- Decision Tree 객체가 학습된 예측 결과를 시각적으로 확인할 수 있음
사용 예시
1
2
3
4
5
6
7
8
9
10
11
12
from sklearn.tree import export_graphviz
from graphviz import Source
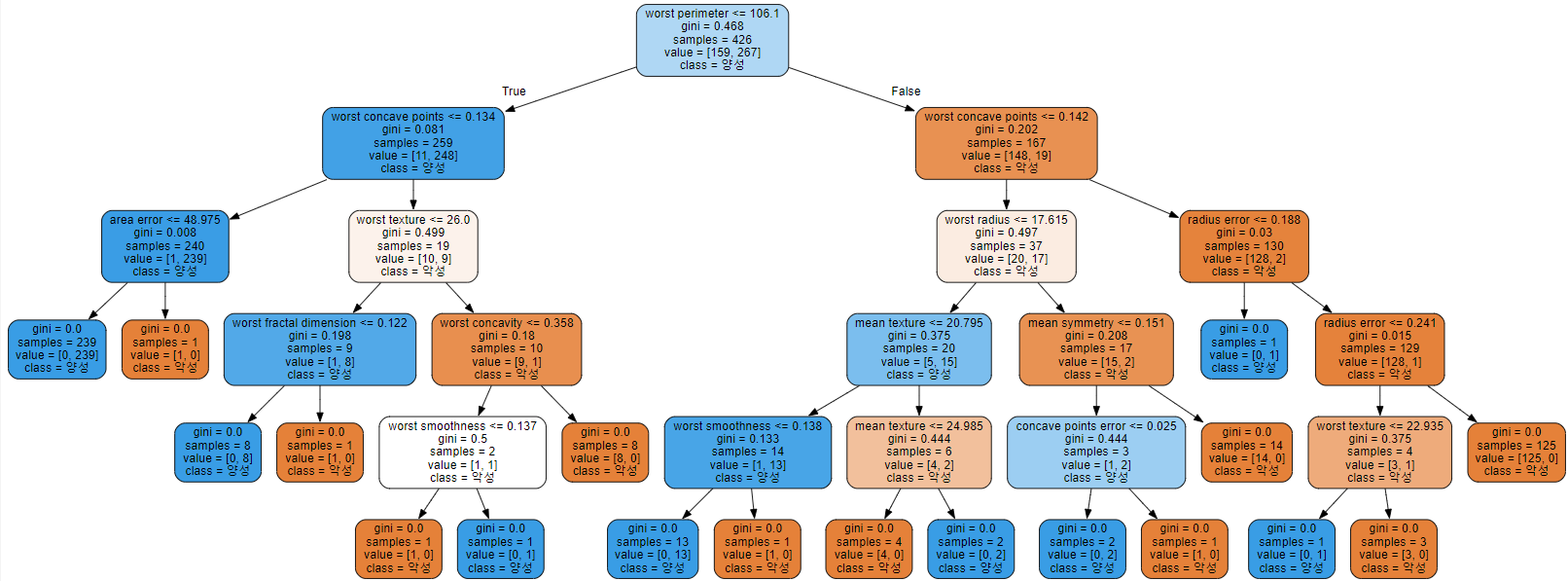
graph = Source(export_graphviz(tree5, # max_depth가 5인 Decision Tree 모델
out_file=r'c:\temp\tree.dot', # 결과 값을 .dot 타입으로 저장
feature_names=data.feature_names,
class_names=['악성', '양성'], # class 이름
rounded=True,
filled=True # 다수 클래스를 색으로 확인할 수 있도록 색을 채운다. 색이 진하면 그 색이 차지하는 비율이 높은 것을 의미
))
graph
- 결과
![graphvizex]()
.dot 파일을 이미지 파일로 변환하는 방법
1
!dot -Tpng c:\temp\tree.dot -o tree.png
- 결과
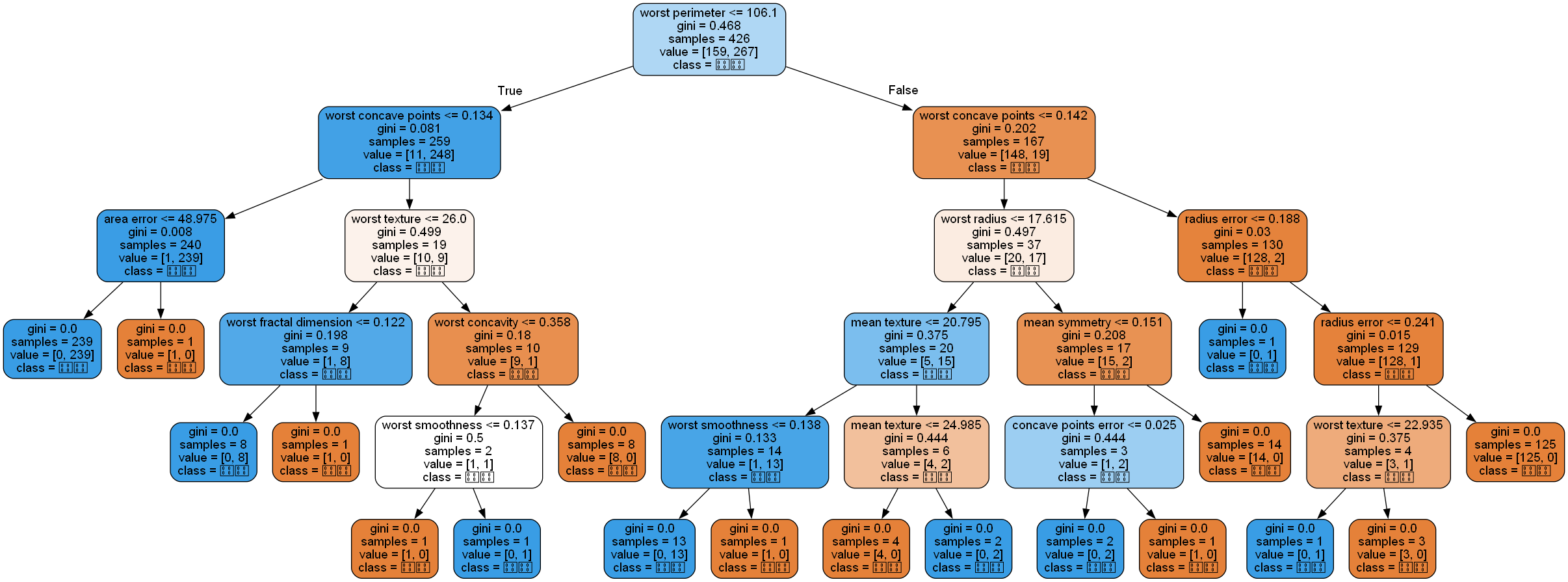
- 대신 한글은 깨지기 때문에 다른 값으로 바꿔야 한다.
Decision Tree 복잡도 제어(규제 파라미터)
- Decision Tree 모델을 복잡하게 하는 것은 노드가 너무 많이 만들어 지는 것이다.
- 노드가 많이 만들어 질수록 훈련데이터셋에 Overfitting 된다.
적절한 시점에 트리 생성을 중단해야 한다.
- 모델의 복잡도 관련 주요 하이퍼파라미터
- max_depth: 트리의 최대 깊이
- max_leaf_nodes : 리프노드 개수
- min_samples_leaf : leaf 노드가 되기위한 최소 샘플수
- 여러개의 하이퍼파라미터를 사용하게 된다면 경우의 수를 다 세야 되기 때문에 for문을 중첩해서 사용해야 한다.
- ex)
max_depth가 [1, 2, 3]이고max_leaf_nodes가 [5, 10]인 하이퍼 파라미터를 사용한다면 총 6(3X2)개를 테스트해서 비교해봐야 한다. - 단순한 반복 작업이기 때문에 이미 함수가 만들어져 있다.(Grid Search)
- ex)
Grid Search
- 모델의 성능을 가장 높게 하는 최적의 하이퍼파라미터를 찾는 방법.
- 하이퍼파라미터 후보들을 하나씩 입력해 모델의 성능이 가장 좋게 만드는 값을 찾는다.
종류
- Grid Search 방식
1
sklearn.model_selection.GridSearchCV
- 시도해볼 하이퍼파라미터들을 지정하면 모든 조합에 대해 교차검증 후 제일 좋은 성능을 내는 하이퍼파라미터 조합을 찾아준다.
- 적은 수의 조합의 경우는 괜찮지만 시도할 하이퍼파라미터와 값들이 많아지면 너무 많은 시간이 걸린다.
- Grid Search 방식
- Random Search 방식
1
sklearn.model_selection.RandomizedSearchCV
- GridSeach와 동일한 방식으로 사용한다.
- 모든 조합을 다 시도하지 않고 임의로 몇개의 조합만 테스트 한다.
GridSearchCV
- https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
- Initializer 매개변수
- estimator: 모델객체 지정
- params : 하이퍼파라미터 목록을 dictionary로 전달 ‘파라미터명’:[파라미터값 list] 형식
- scoring: 평가 지표
- 평가지표문자열: https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
- 생략시 분류는 accuracy, 회귀는 $R^2$ 를 기본 평가지표로 설정한다.
- 여러개일 경우 List로 묶어서 지정
- refit: best parameter를 정할 때 사용할 평가지표
- scoring에 여러개의 평가지표를 설정한 경우 refit을 반드시 설정해야 한다. (순위를 무엇으로 매길지)
- cv: 교차검증시 fold 개수.
- n_jobs: 사용할 CPU 코어 개수 (None:1(기본값), -1: 모든 코어 다 사용)
- 메소드
- fit(X, y): 학습
- predict(X): 분류-추론한 class. 회귀-추론한 값
- 제일 좋은 성능을 낸 모델로 predict()
- predict_proba(X): 분류문제에서 class별 확률을 반환
- 제일 좋은 성능을 낸 모델로 predict_proba() 호출
- 결과 조회 속성
- fit() 후에 호출 할 수 있다.
- cv_results_: 파라미터 조합별 평가 결과를 Dictionary로 반환한다.
- best_params_: 가장 좋은 성능을 낸 parameter 조합을 반환한다.
- best_estimator_: 가장 좋은 성능을 낸 모델을 반환한다.
- best_score_: 가장 좋은 점수 반환한다.
RandomizedSearchCV
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html
- Initializer 매개변수
- estimator: 모델객체 지정
- param_distributions: 하이퍼파라미터 목록을 dictionary로 전달 ‘파라미터명’:[파라미터값 list] 형식
- n_iter: 전체 조합중 몇개의 조합을 테스트 할지 개수 설정
- scoring: 평가 지표
- refit: best parameter를 정할 때 사용할 평가지표. Scoring에 여러개의 평가지표를 설정한 경우 설정.
- cv: 교차검증시 fold 개수.
- n_jobs: 사용할 CPU 코어 개수 (None:1(기본값), -1: 모든 코어 다 사용)
- 메소드
- fit(X, y): 학습
- predict(X): 분류-추론한 class. 회귀-추론한 값
- 제일 좋은 성능을 낸 모델로 predict()
- predict_proba(X): 분류문제에서 class별 확률을 반환
- 제일 좋은 성능을 낸 모델로 predict_proba() 호출
- 결과 조회 속성
- fit() 후에 호출 할 수 있다.
- cv_results_: 파라미터 조합별 평가 결과를 Dictionary로 반환한다.
- best_params_: 가장 좋은 성능을 낸 parameter 조합을 반환한다.
- best_estimator_: 가장 좋은 성능을 낸 모델을 반환한다.
- best_score_: 가장 좋은 점수 반환한다.
Pipeline(파이프라인)
Pipeline이란?
- 여러 단계의 머신러닝 프로세스 (전처리의 각 단계, 모델생성, 학습) 처리 과정을 설정하여 한번에 처리되도록 한다.
- 파이프라인은 전처리를 진행하는 여러개의 Transformer(변환기)와 마지막에 Transformer 또는 Estimator(추정기)로 이루어져있다.
- 전처리 작업 파이프라인
- Transformer로만 구성
- 전체 프로세스 파이프 라인
- 마지막에 Estimator를 넣는다.
Pipeline 을 이용한 학습
- pipeline.fit()
- 각 순서대로 각 변환기의 fit_transform()이 실행되고 결과가 다음 단계로 전달된다. 마지막 단계에서는 fit()만 호출한다.
- 마지막이 추정기일때 사용
- pipeline.fit_transform()
- fit()과 동일하나 마지막 단계에서도 fit_transform()이 실행된다.
- 전처리 작업 파이프라인(모든 단계가 변환기)일 때 사용
- 마지막이 추정기(모델) 일 경우
- predict(X), predict_proba(X)
- 추정기를 이용해서 X에 대한 결과를 추론
- 모델 앞에 있는 변환기들을 이용해서 transform() 그 처리결과를 다음 단계로 전달
GridSearch에서 Pipeline 사용
- 하이퍼파라미터 지정시 파이프라인
프로세스이름__하이퍼파라미터형식으로 지정한다.- Pipeline 생성
- GridSearchCV의 estimator에 pipeline 등록
make_pipeline() 함수를 이용한 파이프라인 생성을 편리하게 하기
- make_pipeline(변환기객체, 변환기객체, ….., 추정기객체): Pipeline
- 프로세스의 이름을 프로세스클래스이름(소문자로변환)으로 해서 Pipeline을 생성.
- GridSearch를 사용하지 않을 때 주로 사용